gamervivek
Regular
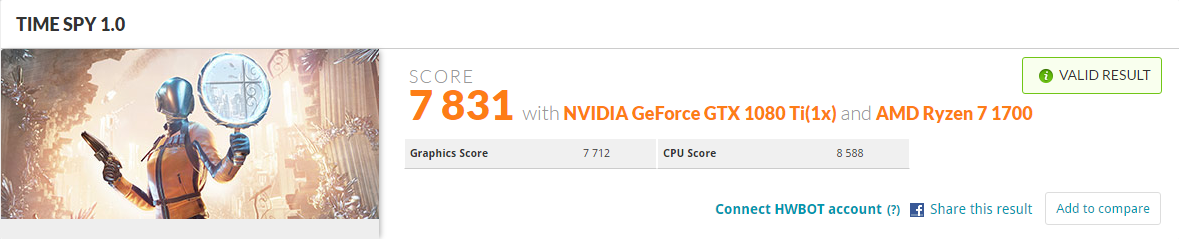
If that's at stock then that's a good improvement since the benchmark was released, I guess most of the benches I looked at were at the benchmark's release or pascal cards' because many recent user benches come up with 5.2k-5.3k as opposed to 5k+ from last year.
https://www.overclock3d.net/gfx/articles/2016/07/16120648644l.jpg
http://www.overclock.net/content/type/61/id/2829273/
https://www.extremetech.com/wp-content/uploads/2016/07/timespy-3.png
Hopefully the 80% of AMD driver team's workhours get similar gains for Vega before release because right now it doesn't look nice even for 1.2Ghz.
https://www.overclock3d.net/gfx/articles/2016/07/16120648644l.jpg
http://www.overclock.net/content/type/61/id/2829273/
https://www.extremetech.com/wp-content/uploads/2016/07/timespy-3.png
Hopefully the 80% of AMD driver team's workhours get similar gains for Vega before release because right now it doesn't look nice even for 1.2Ghz.