
Stereo photogrammetry works best with even lighting, so that it can match patterns not affected by shadows and such, focusing only on the skin texture. It's also taking into account the camera positions and it prefers to have the background masked out. Very high resolution, low amounts of noise and tight focus help a lot too. All of these seem to go way above what a single camera can do...
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Stereo Vision and Time of Flight setups for Face Scanning
- Thread starter onQ
- Start date
Apparently the process uses a lot of power, 2K developers said that the whole process takes about 3 minutes using the PS4 and Xbox One on full power -power that they loved, btw- until all the details are processed, iirc.They don't use a single shot.
http://support.2k.com/hc/en-us/articles/203696076-How-to-Scan-Your-Face-in-NBA-2K15
Laa, what shaving cream do you use if that's not asking much? Your face looks really smooth, man, it has to be either the cream or the aftershave.
I don't have hair on my chest, naturally, for instance, my siblings say it's odd, but that's how it is. Not that I grow much of a beard either, but my two days sparse but valiant growth is noticeable of course.
")
LOL thanks
I prefer Gillette sensitive foam, although these daysI only shave like once per week at most. Then again it seems that any facial hair under 1mm wouldn't make much of a difference for the scanning. Eyelashes and eyebrows are an issue but getting rid of that is of course not an option, but it's fairly easy to compensate in zbrush or mudbox, and you'll have to do a cleanup pass anyway.
Chest, arm and leg hair for full body scans is another matter, it adds a lot of noise and hides surface details like veins or tendonds (but ours isn't precise enough to register skin pore detail) so it must go away. Everyone also has a layer of "peach fuzz", tiny and transparent white layer of sparse fur, but it also seems to have no effect, yet it's pretty important for convincing CG renders. I wonder how games are going to solve that.
Body hair takes about a month to grow back to an acceptable length BTW. The sacrifices you make for science... been bugged about it a LOT by my coworker pals.
I prefer Gillette sensitive foam, although these daysI only shave like once per week at most. Then again it seems that any facial hair under 1mm wouldn't make much of a difference for the scanning. Eyelashes and eyebrows are an issue but getting rid of that is of course not an option, but it's fairly easy to compensate in zbrush or mudbox, and you'll have to do a cleanup pass anyway.
Chest, arm and leg hair for full body scans is another matter, it adds a lot of noise and hides surface details like veins or tendonds (but ours isn't precise enough to register skin pore detail) so it must go away. Everyone also has a layer of "peach fuzz", tiny and transparent white layer of sparse fur, but it also seems to have no effect, yet it's pretty important for convincing CG renders. I wonder how games are going to solve that.
Body hair takes about a month to grow back to an acceptable length BTW. The sacrifices you make for science... been bugged about it a LOT by my coworker pals.
I haven't read everything linked here, but do we even know for sure it uses depth information from Kinect at all? It may well just be designed for using a single camera input. May not even be using stereoscopy on PS4 either.
If it's only using one camera Kinect 2.0 should be doing the better job with it's 1080P RGB vs PS4 camera 1280 x 800 RGB ( in bright light anyway) & they probably would have added the feature to PC.
Rurouni
Veteran
I think they only use background removal and not scanning the face topology directly (directly as in receiving the depth data of the face from the cam). They probably use their own solution which probably based on photogrammetry.
The reason why it isn't offered on PC probably because it doesn't have background removal, thus extra work to implement background removal (how? Forcing player to scan with a plain background?).
Is there a comparison about the RGB camera image quality? I can imagine that since probably the lighting situation isn't ideal, the cam that has better low light performance should yield a better result.
The reason why it isn't offered on PC probably because it doesn't have background removal, thus extra work to implement background removal (how? Forcing player to scan with a plain background?).
Is there a comparison about the RGB camera image quality? I can imagine that since probably the lighting situation isn't ideal, the cam that has better low light performance should yield a better result.
I think the main reason not to support it on PC would more likely be that there are about 3000 models of webcams out there in the wild, and if the functionality is as spotty as it is with just the PS Camera and Kinect, then just imagine ...
If they use the Kinect camera fully, I can almost not imagine the issues we're now seeing. The actual resolution of the camera isn't that important - the precision, contrast and framerate could be more helpful, and I think the PS Camera can do a higher res at 60fps?
If they use the Kinect camera fully, I can almost not imagine the issues we're now seeing. The actual resolution of the camera isn't that important - the precision, contrast and framerate could be more helpful, and I think the PS Camera can do a higher res at 60fps?
I think they only use background removal and not scanning the face topology directly (directly as in receiving the depth data of the face from the cam). They probably use their own solution which probably based on photogrammetry.
The reason why it isn't offered on PC probably because it doesn't have background removal, thus extra work to implement background removal (how? Forcing player to scan with a plain background?).
Is there a comparison about the RGB camera image quality? I can imagine that since probably the lighting situation isn't ideal, the cam that has better low light performance should yield a better result.
Background removal is still using a secondary camera which would be the IR camera for Kinect & the stereo vision for PS4 camera.
Maybe the background removal is being done in hardware giving PS4 an advantage in this task or it's just that both the cameras are the same resolution making it better at background removal. .
I think the main reason not to support it on PC would more likely be that there are about 3000 models of webcams out there in the wild, and if the functionality is as spotty as it is with just the PS Camera and Kinect, then just imagine ...
If they use the Kinect camera fully, I can almost not imagine the issues we're now seeing. The actual resolution of the camera isn't that important - the precision, contrast and framerate could be more helpful, and I think the PS Camera can do a higher res at 60fps?
Good point.
Background removal is trivial with Kinect. You just generate a mask for any depth beyond where the head is.Background removal is still using a secondary camera which would be the IR camera for Kinect & the stereo vision for PS4 camera.
Maybe the background removal is being done in hardware giving PS4 an advantage in this task or it's just that both the cameras are the same resolution making it better at background removal.
Background removal is trivial with Kinect. You just generate a mask for any depth beyond where the head is.
Yeah but how clean is the background removal when there is movement? What might look clean to our eyes might not be clean to the software.
It should be extremely clean as the time of flight of the photons, which means a picosecond level 'shutter speed'. Compare that to the 1/60th second or similar blur-fest of an optical capture... And it's certainly a damned sight cleaner than trying to identify the background from stereo images which can fairly in considerable chunks if there isn't enough visual contrast.
It should be extremely clean as the time of flight of the photons, which means a picosecond level 'shutter speed'. Compare that to the 1/60th second or similar blur-fest of an optical capture... And it's certainly a damned sight cleaner than trying to identify the background from stereo images which can fairly in considerable chunks if there isn't enough visual contrast.
The problem would be how well the time of flight background removal is syncing up with the video feed.
Edit: I think depth information is being used how else would bugs like this be happening?
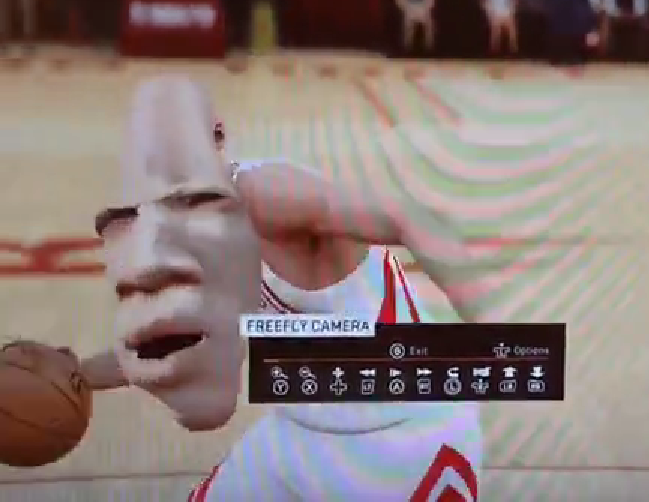
Last edited by a moderator:
I think the snake-dude and easter-island head dudes look kind of awesome - and funny.
They should make a sequel to M.U.D.S with those kind of models.
(M.U.D.S were a old Amiga game - short for Mean Ugly Dirty Sport, wich were a mix of Rugby and soccer, you could bribe the ball wich were a turtle, and there were water-pits with aligators infront of the goalposts, on one teams home-arena).
Might be abit off topic - but it would be an awesome feature, if you could change the entire team, to various people like this..
They should make a sequel to M.U.D.S with those kind of models.
(M.U.D.S were a old Amiga game - short for Mean Ugly Dirty Sport, wich were a mix of Rugby and soccer, you could bribe the ball wich were a turtle, and there were water-pits with aligators infront of the goalposts, on one teams home-arena).
Might be abit off topic - but it would be an awesome feature, if you could change the entire team, to various people like this..
Last edited by a moderator:
Again, trivial. For starters, you get both feeds at the same time frame-sync'd, otherwise the system's inept. But even if there's a bit of lag, you can easily offset one video by however many frames to line it up.The problem would be how well the time of flight background removal is syncing up with the video feed.
Without seeing the results you're talking about, I can only provide some general insight. The 3D depth image resolution isn't a problem because the face is vacuum-formed over the point-cloud. Depth resolution is too small, but accumulating over multiple samples can be very accurate. We need only look at the incredible results achieved with the crusty methods of Kinect 1 regards realtime scanning. Disparity between depth and video images is irrelevant. You'll crop the images and scale, mapping based on face recognition tech.
Creating a 3D depth map from stereo is a lot harder and prone to errors. It'll no doubt work in the same way, creating a volume and shrink-wrapping the head onto it. So I'd be inclined to believe that it's the libraries giving poor results on XB1, if they are worse, or possibly not a best-case use of the tech. Does the user have to move forwards and backwards from the camera, or move it around their head?
StereoVision seems to have come a long way this depth map look pretty good.
Edit: never mind it's a hybrid.
Last edited by a moderator:
PS4's camera is extremely underutilized. Its been a year and we havent seen almost anything
I don't think many devs are willing to take a chance creating a game for a sub-platform with a user base that's maybe below 20% of the main user base.This is the reason why I feel that Sony should bundle the Camera into the package & make it a standard part of the PS4 before there 1st price drop.
I don't think many devs are willing to take a chance creating a game for a sub-platform with a user base that's maybe below 20% of the main user base.This is the reason why I feel that Sony should bundle the Camera into the package & make it a standard part of the PS4 before there 1st price drop.
I agree that it should become standard and I understand why devs arent doing much with it. But I was expecting Sony to promote it more and develop more apps and uses for it.
Its 3D depth capabilities have barely been demonstrated by Sony which was the point of using a stereo camera. Its like they temporarily threw it in just to have something to pevent MS from having a strong competitive advantage to show
Similar threads
- Replies
- 26
- Views
- 2K
- Locked
- Replies
- 27
- Views
- 2K
- Replies
- 21
- Views
- 6K