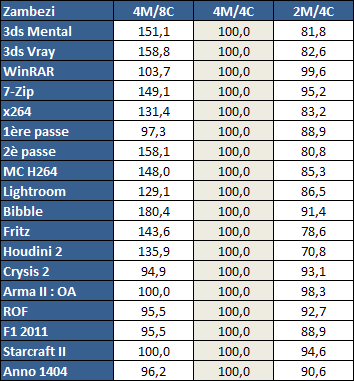
Did anyone seen some multitasking benchmarks for the dozer? If it needs those threads so badly  .
.
A also guess this could be a problem in future if software cant catch up to the cores. 8 or 12 cores will just sit idle and wont bring much improvement if u dont use it for rendering or encoding.
.A also guess this could be a problem in future if software cant catch up to the cores. 8 or 12 cores will just sit idle and wont bring much improvement if u dont use it for rendering or encoding.
Last edited by a moderator: