
Its not really deeper in the pipeline, both architectures are similar in that regard, its just that nV has more tessellation (polymorph) units. But over all, you still need serious amounts of shader power to do tessellation and displacement.
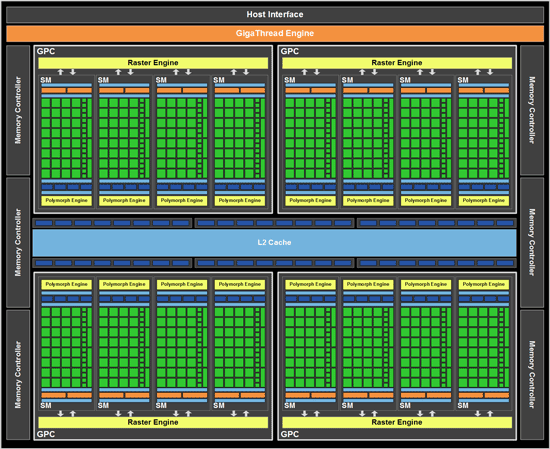
From the block diagram u can see that a single polymorph engine has only 32 SP-s aviable max. Cant do anything else with the others. So the whole tesselation pipeline Hull shader, Tesselator, Domain shader (so the displacement too) is running on the same 32 SP-s. Just paralel with the other 15. At least thats what i see from the diagram.
 Maybe they can keep track of each other trough the L2 cache but cant help each other directly.
Maybe they can keep track of each other trough the L2 cache but cant help each other directly.Right now even a 2 GPC and 8 polymorph card would be miles ahead of cypress in tesselation. But that could change with the next radeons.