Outstanding job again Dave!!
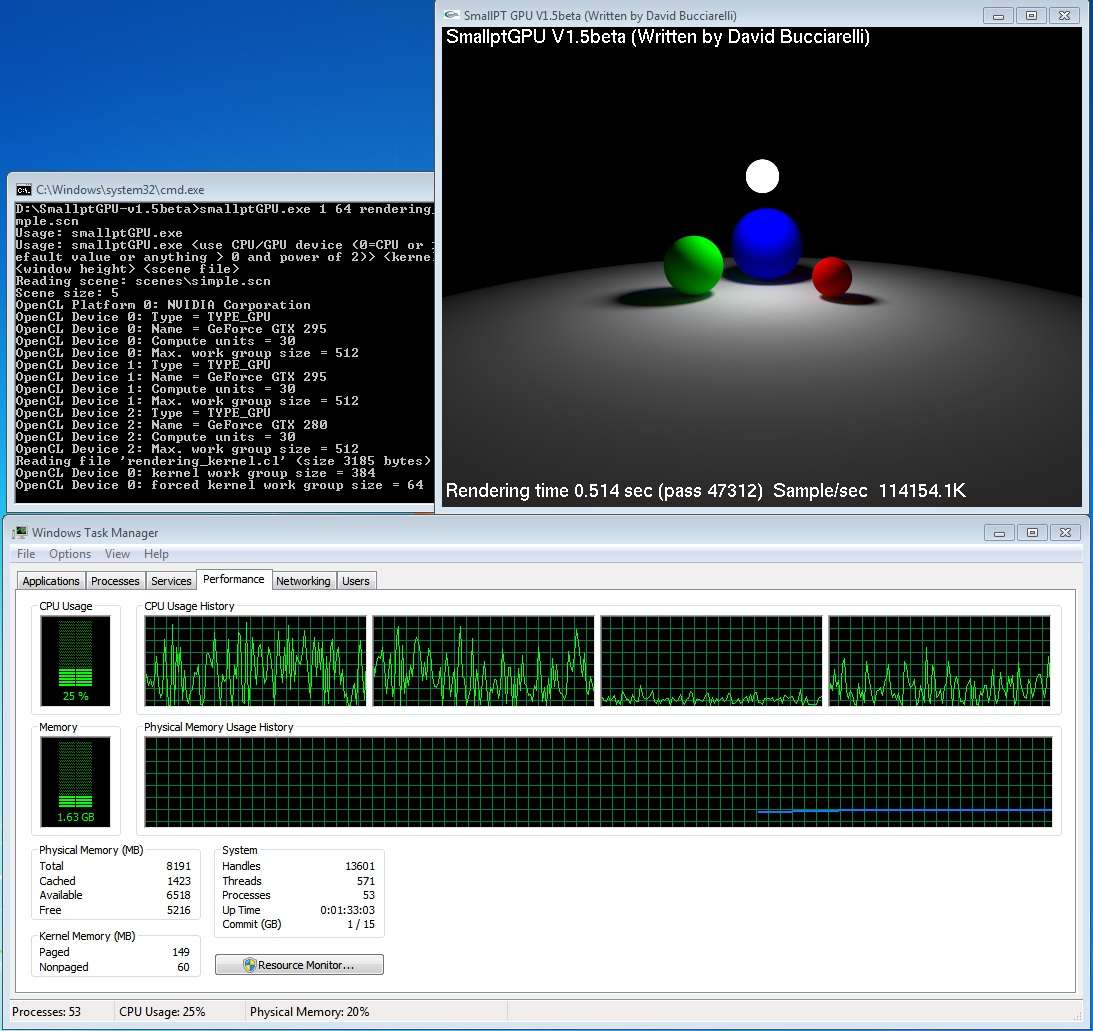
By manually adjusting the workload, I now can get 5173.9K Samples/sec. (A new record on my system.)
First 1/2 of my 295 - 96%
Second 1/2 of my 295 - 97%
280 Dedicated PhysX - 96%
Q6600 - 30% (Exactly the same as the first 2.0Alpha, without the manual GPU workload distribution feature.)
Thanks Talonman, good to see it works fine
")
I have received the parts for my new PC yesterday (wow, the 5870 is really HUGE
). Once I have installed everything (i.e. 2x OS, all the tools, etc.) I'm thinking to buy a cheap NVIDIA card for my old PC. This should be finally allow me to squeeze some better performance out of NVIDIA hardware.I was thinking to buy a 250GTS for my old PC as cheap test platform. Any better idea ? I don't know the line of NVIDIA cards very well.