Silent_Buddha
Legend
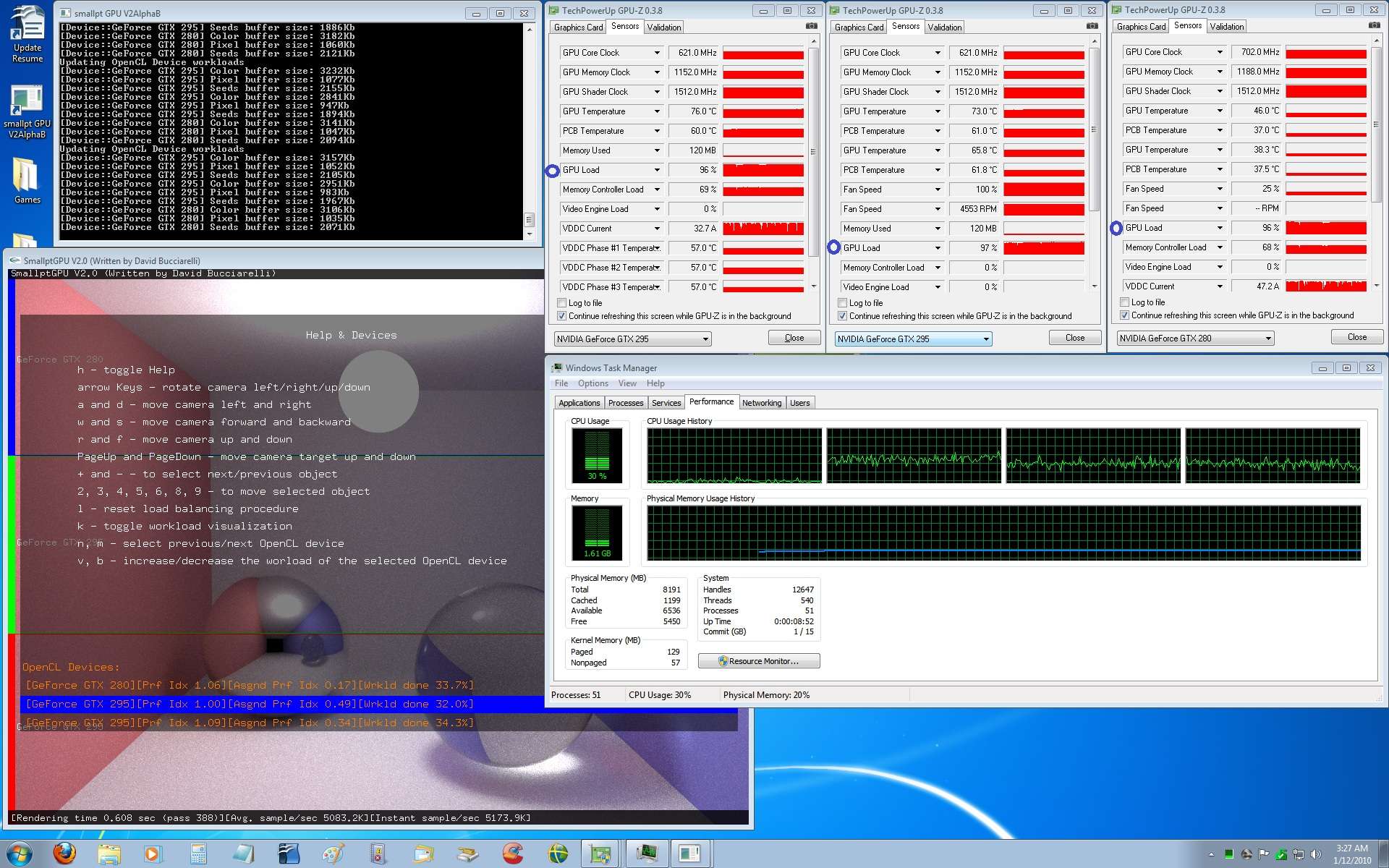
@Silent_Buddha: yup, the AMD/ATI OpenCL CPU device spawns as many threads as the cores available. At the moment I have the opposite problem, I would like to have some direct control on the number thread spawned in order to not overload the CPU (and slow down threads dedicated to drive the GPUs).
I was just wondering about that myself. That was my next question for you. Whether there was a way to limit the number of threads/number of cores used on a CPU. As I'd imagine it could be problematic in say a game for instance, if the core game required 1-2 cores for good performance, but would then like anything using OpenCL to be able to fully occupy all remaining cores.
Regards,
SB
 Everything works fine under Linux ... quite strange. Well, it may crash but you can give it a try.
Everything works fine under Linux ... quite strange. Well, it may crash but you can give it a try.