
this might be feasible only if you're willing to trade off the two not interacting with each other. Sounds a lot like what we have today already.But it's often MANY% static. Maybe some engines might chose to use two separate BVHs and traverse both simultaneously. A super tight and optimized one baked offline + a dynamic slightly less optimal to traverse but quick to build one generated in real time just for the dynamic portion of the scene. The speedup might offset the overhead.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Next gen lighting technologies - voxelised, traced, and everything else *spawn*
- Thread starter Scott_Arm
- Start date
this might be feasible only if you're willing to trade off the two not interacting with each other
Why? Trace the same ray in each, see which one spits the closest hit and shade that.
At first though I think that's only going to work for primary rays I think. Once you get to bouncing that isn't going to work as well. You'd have to issue 2 rays for both for every single intersection. That's a lot of interaction between two objects and one BVH may not process as fast as the other and then you'd have sync points to consider. You're also double spawning rays for everything, sounds extremely heavy on bandwidth and you're going to wreck any sort of ray coherency you have.Why? Trace the same ray in each, see which one spits the closest hit and shade that.
At first though I think that's only going to work for primary rays I think. Once you get to bouncing that isn't going to work as well. You'd have to issue 2 rays for both for every single intersection. That's a lot of interaction between two objects and one BVH may not process as fast as the other and then you'd have sync points to consider. You're also double spawning rays for everything, sounds extremely heavy on bandwidth and you're going to wreck any sort of ray coherency you have.
Yeah, I'm assuming here that for the forseable future, games won't be doing multi-bounce anything, and also I also have the hunch most devs will land into deferred shading for RT hits, with even some steps of software driven ray buffering and clustering.
Sure, but neither triangle nor box intersection instructions may be available to shaders.And they aren't on Turing?
On AMD it might be, because shaders control outer traversal loop, they feed the intersection units with data. Question is how much of traversal logic and data processing is handled by shaders too. I can't make enough sense of TMU patent to be sure.
But we have to wait and see. Everybody now seems to be sure real HW matches TMU patent, but no confirmation on that? And even if, AMD could have added fixed function outer loop processing, ending up close to NVs RT cores.
Or they have both: FF processing and optional shader driven to support traversal shaders where needed.
Intels traversal shader paper proposes a best of both solution, where only certain nodes trigger processing intervention from programmable shaders, IIRC.
I think this makes sense. Because a ray box intersection instruction alone would not help much. Even without a special instruction we can do this faster than the loading of box coordinates from memory takes.
Triangle intersection is more complex, but still i guess HW RT would mean some hardwired BVH restrictions and processing to be effective enough.
Don't know for ray-AABB intersection test probably on Turing.
I suppose for static part of the scene.
No, in typical RT work, 80% of ray intersctions are against BVH node bounding boxes until we find some triangles, which then ar only 20 % of intersection tests. (randomly guessed numbers, depends on data)
So RTX has HW box intersection for sure.
And there likely is no difference between dynamic and static BVH while tracing.
We can optimize harder for static BVH build (SAH is expensive), but likely we also build dynamic BVH only once, using the same expensive optimization, and we keep the optimized tree structure static, but only refit the bounding box coordinates after animation.
So we have optimized precomputed bottom level BVH for everything. The myth 'tree building is too expensive for realtime' was never true.
This works for almost all things we see in games. Only a totally shape changing stuff like surface of fluid would require a full rebuild of BVH.
Office Corridor [UE4 / Real-Time Ray Tracing]
April 15, 2020

https://www.artstation.com/artwork/nQrD0X
April 15, 2020
This project was for learning more about modular environments and the real-time ray tracing function in Unreal Engine. Inspired by the game Control. Modelled with Blender, textured with Substance Suite and rendered in Unreal Engine.
...
About the wood ... there is also a glass panel in front of it
https://www.artstation.com/artwork/nQrD0X
No, in typical RT work, 80% of ray intersctions are against BVH node bounding boxes until we find some triangles, which then ar only 20 % of intersection tests. (randomly guessed numbers, depends on data)
So RTX has HW box intersection for sure.
And there likely is no difference between dynamic and static BVH while tracing.
We can optimize harder for static BVH build (SAH is expensive), but likely we also build dynamic BVH only once, using the same expensive optimization, and we keep the optimized tree structure static, but only refit the bounding box coordinates after animation.
So we have optimized precomputed bottom level BVH for everything. The myth 'tree building is too expensive for realtime' was never true.
This works for almost all things we see in games. Only a totally shape changing stuff like surface of fluid would require a full rebuild of BVH.
https://github.com/GPSnoopy/RayTracingInVulkan
Yes you have reason maybe using lower precision from what this guy experiment find.
- I suspect the RTX 20 series RT cores to implement ray-AABB collision detection using reduced float precision. Early in the development, when trying to get the sphere procedural rendering to work, reporting an intersection every time the rint shader is invoked allowed to visualise the AABB of each procedural instance. The rendering of the bounding volume had many artifacts around the boxes edges, typical of reduced precision.
Probably faster than ray-triangle intersection on RTX.
Last edited:
I'm fairly sure that NV can expose box intersection results back to shaders if this will be needed and this will essentially work as its supposed to on RDNA2.Sure, but neither triangle nor box intersection instructions may be available to shaders.
Isn't this more or less what is allowed by DXR 1.0 even?Intels traversal shader paper proposes a best of both solution, where only certain nodes trigger processing intervention from programmable shaders, IIRC.
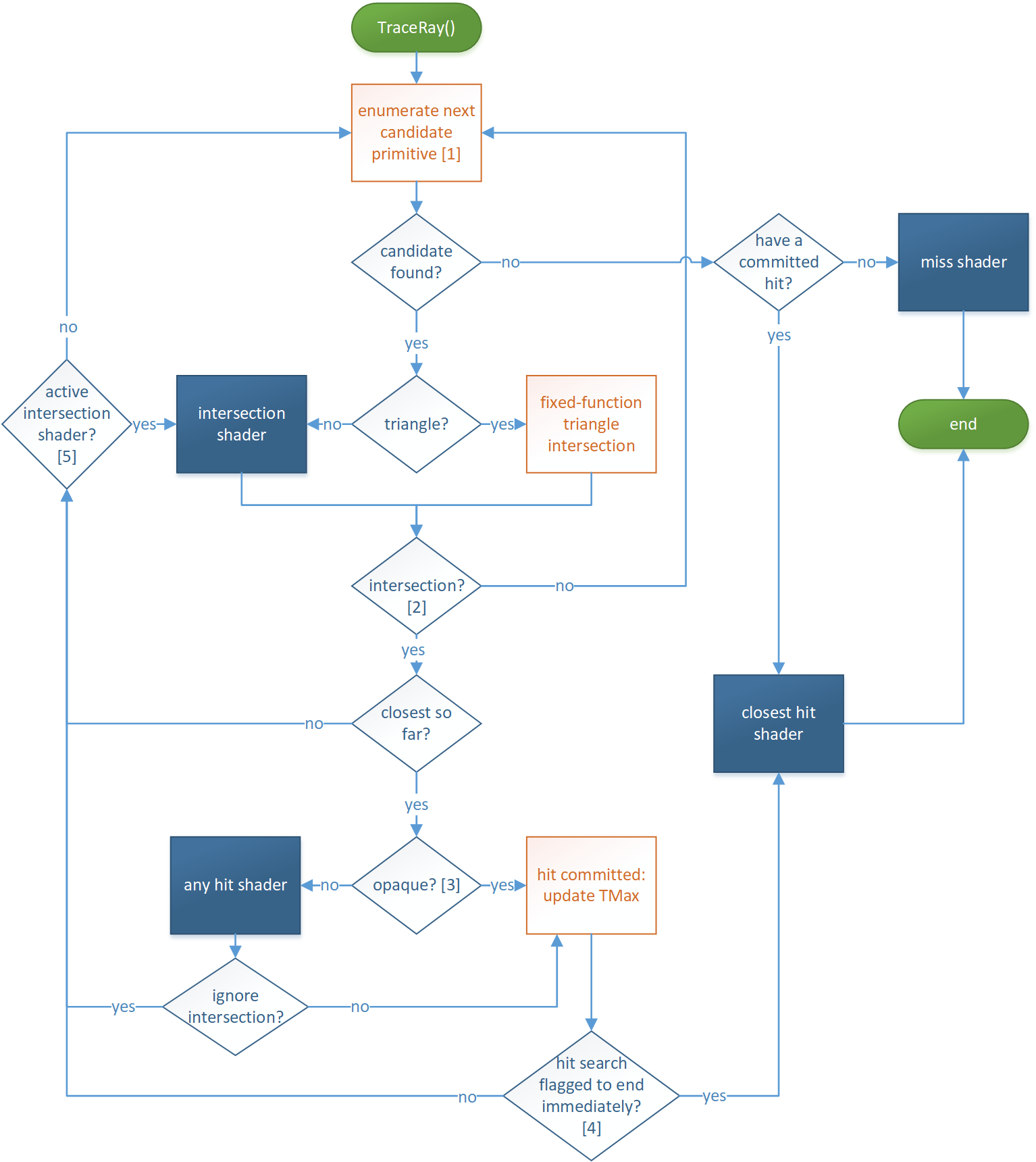
No, in typical RT work, 80% of ray intersctions are against BVH node bounding boxes until we find some triangles, which then ar only 20 % of intersection tests. (randomly guessed numbers, depends on data)
So RTX has HW box intersection for sure.
And there likely is no difference between dynamic and static BVH while tracing.
We can optimize harder for static BVH build (SAH is expensive), but likely we also build dynamic BVH only once, using the same expensive optimization, and we keep the optimized tree structure static, but only refit the bounding box coordinates after animation.
So we have optimized precomputed bottom level BVH for everything. The myth 'tree building is too expensive for realtime' was never true.
This works for almost all things we see in games. Only a totally shape changing stuff like surface of fluid would require a full rebuild of BVH.
https://computergraphics.stackexcha...r-voxel-grids-and-rtx-accelerated-ray-tracing
Here it seems, it is useful only when you use triangle after maybe it is the same on RDNA2.
Question: I've been looking to play with ray tracing, starting with a simplest of minecraft clones (making something more akin to cave game, for starter).
I figured I'd define a voxel as a primitive and then use the regular voxel grid to trace the rays. I don't need to test (look) for intersections here, I can precisely calculate them, tracing the ray voxel by voxel.
However, I do have an RTX card which does accelerate ray tracing with dedicated hardware, and I may be able to get faster results if I were to leverage it.
From what I gathered, one of the components of the RTX system (or any ray tracer, really) is an acceleration structure that speeds up the process of testing for intersections.
You give the card an octree or a BVH (or something similar) and it uses it to quickly find the closest hit (or any other hits, for that matter).
If I'm not mistaken, the hardware accelerated part here is the hit test. It's power is in the ability to test many primitives against one or more rays in a very short amount of time.
Given the method I'm using for ray tracing, that is the one part that I don't really need, since I don't need to search for which primitives the ray intersects (I calculate them explicitly), I just need to check where the intersection on them is.
Am I wrong? Can the architecture be used to accelerate what I'm doing? If so, is it due to the fact that I misunderstood how it works, or can I adapt my plan in order to make it more friendly to the architecture, making the resulting plan faster than the original?
Answer:
As you said, the RTX Turing architecture comes with wired primitive-ray intersection, (to be more specific, triangle-ray intersection). The BVH is built by specifying the Bounding Box program to OptiX, the signature of which is:
RT_PROGRAM void my_boundingbox_build_program( int, float result[6] )
As you can guess, the result must contain the minimun (3 first components) and maximum (3 last components) bounds of the bounding box. You can use this to build virtual bounding boxes even if you have no geometry (for instance, a chunk of 16x16x16 voxels).
When you perform rtTrace , the OptiX API will detect the collision through the BVH which it has build with the help of your bounding box program. In that momment, it will call the Intersection program, which you can specify and which signature is:
RT_PROGRAM void my_intersection_program( int prim_index )
Where you will report any possible intersection within your 16x16x16 chunk of voxels (obviously you can ignore the prim_index, which is only useful when using geometry primitives).
Now, if you would use their special structure RTgeometrytriangles , the Turing RTX architecture would be able to make use of the wired primitive intersection, which is where performance boost would be gained, and you would not need to implement your own intersection program.
To sumarize: Since you are not using the specific RTgeometrytriangles , you will not access the intersection performance boost from the Turing architecture.
EDIT: Sorry I was thinking maybe RDNA2 can accelerate intersection test with other things than triangle. Maybe this is false and exactly like describe here.
My memory is horrible, but wasn't there specs where doing BVH testing had 2 different forms, with one being roughly half the rate perhaps even a third of the other? For the life of me, I can't remember if it was for Nvidia or if it was Triangles vs Boxes.
But for some reason it feels like there's still a lot of unknowns on AMD's RT despite having a patent or two about it. As with all things, feelings can easily be wrong.
But for some reason it feels like there's still a lot of unknowns on AMD's RT despite having a patent or two about it. As with all things, feelings can easily be wrong.
I still have no experience with DXR, so i might miss some things and get some wrong. But if DXR had support fro traversal shaders, neither MS nor Intel would propose them as future addition.Isn't this more or less what is allowed by DXR 1.0 even?
But we could emulate it:
Use custom intersection shader boxes to trigger shader execution, and here we could just launch a new ray, eventually in another less detailed version of the scene.
The downside is probably: If we decide to keep the current lod, we still need to start a new ray from scratch, loosing the traversal work already done and needing to restart from the root.
Would make no sense yet. Which other primitive would be worth it? Nurbs? Catmull Clark subdiv? ... nothing of this became widely used in games runtime data, and all of it boils down to triangles anyways.My bad I was thinking RDNA2 GPU can accelerate intersection test with other primitives than triangle, probably not the case at all...
The only problem i see with current triangles in boxes is the black boxed relation between them. I want to keep the BVH static, but have access to box dimensions and triangles shape. And i want to disable leaf nodes, set the parent as the leaf instead and put low detailed triangles into it.
I'm sure both NV and AMD could support such options without any need to rebuild trees. No fancy traversal shaders would be necessary to allow dynamic detail.
But i'm requesting a feature although nobody (including myself) has such an advanced solution to the LOD problem yet. So far we could not solve it with rasterization, so requesting RT support for progressive mesh methods is far fetched at the moment, i have to admit
")
I still have no experience with DXR, so i might miss some things and get some wrong. But if DXR had support fro traversal shaders, neither MS nor Intel would propose them as future addition.
But we could emulate it:
Use custom intersection shader boxes to trigger shader execution, and here we could just launch a new ray, eventually in another less detailed version of the scene.
The downside is probably: If we decide to keep the current lod, we still need to start a new ray from scratch, loosing the traversal work already done and needing to restart from the root.
Would make no sense yet. Which other primitive would be worth it? Nurbs? Catmull Clark subdiv? ... nothing of this became widely used in games runtime data, and all of it boils down to triangles anyways.
The only problem i see with current triangles in boxes is the black boxed relation between them. I want to keep the BVH static, but have access to box dimensions and triangles shape. And i want to disable leaf nodes, set the parent as the leaf instead and put low detailed triangles into it.
I'm sure both NV and AMD could support such options without any need to rebuild trees. No fancy traversal shaders would be necessary to allow dynamic detail.
But i'm requesting a feature although nobody (including myself) has such an advanced solution to the LOD problem yet. So far we could not solve it with rasterization, so requesting RT support for progressive mesh methods is far fetched at the moment, i have to admit
It's not only games that benefit from ray tracing acceleration
I still have no experience with DXR, so i might miss some things and get some wrong. But if DXR had support fro traversal shaders, neither MS nor Intel would propose them as future addition.
But we could emulate it:
Use custom intersection shader boxes to trigger shader execution, and here we could just launch a new ray, eventually in another less detailed version of the scene.
The downside is probably: If we decide to keep the current lod, we still need to start a new ray from scratch, loosing the traversal work already done and needing to restart from the root.
Would make no sense yet. Which other primitive would be worth it? Nurbs? Catmull Clark subdiv? ... nothing of this became widely used in games runtime data, and all of it boils down to triangles anyways.
The only problem i see with current triangles in boxes is the black boxed relation between them. I want to keep the BVH static, but have access to box dimensions and triangles shape. And i want to disable leaf nodes, set the parent as the leaf instead and put low detailed triangles into it.
I'm sure both NV and AMD could support such options without any need to rebuild trees. No fancy traversal shaders would be necessary to allow dynamic detail.
But i'm requesting a feature although nobody (including myself) has such an advanced solution to the LOD problem yet. So far we could not solve it with rasterization, so requesting RT support for progressive mesh methods is far fetched at the moment, i have to admit
It would be at least useful for raytracing in Dreams probably or voxel based games.
Yeah, but movies using CC or Nurbs can convert their stuff to triangles (which they have to do anyways) and use RTX. Everybody happy, and NV will agree because their patch offerings never payed off.It's not only games that benefit from ray tracing acceleration
For movie industry, 'triangles only' is surely no problem, but limited options about instancing might be, and ofc limited RAM.
Now with inline RT from compute, i guess it's possible to use RT HW to hit a bounding box, and then you could even use parallel algorithm to intersect your custom geometry.It would be at least useful for raytracing in Dreams probably or voxel based games.
The 'single threaded rays limitation' from DXR 1.0 seems gone. (IDK if it's possible to continue a ray that misses custom intersection, or if full restart is necessary - probably it's possible to continue.)
But could Dreams be traced efficiently just because it's technically possible? I wish i knew.
The problem is we inherit the divergence from the RT system: The hit points we get within our compute workgroup will be scattered across the scene. So parallel algorithms make no sense and we can just use the single threaded custom intersection shaders from DXR 1.0.
To improve this, we would need ray reordering in hardware to cluster all hits at a certain box together, but then we end up with low threads saturation in our CU. Probably nor really an improvement.
So if you ask me what's necessary to use RT for alternative geometry, the answer is the exact same as for my LOD requests: Having control over BVH construction and dynamic modification.
I do not need custom intersection instructions to intersect a ray with a sphere or box - that's super cheap with regular CUs already.
... still curious if Sony could offer more flexibility than MS plans to do. But MS can change their mind any time if necessary.
Even without RT hardware, I think so. SDF strikes me as similar to CSG is terms of mathematical resolving.But could Dreams be traced efficiently just because it's technically possible? I wish i knew.
One question in my mind is that how willing are developers to spend time with low level api when even the high level API seems to be too much time(aka. money) to invest in? Does low level API even make sense until the higher level API use is widespread and there is widespread requests from many developers to add specific bits of programmability into the hw/api. These requests would likely come to public via gdc talks/post mortems/tweets where the big players would say hey we did this, its shipping, now we know we need x to make things that much better for next title.
This probably is one of those cases where evolution happens fairly slowly but surely. There is a starting point and things will get slowly better(faster, more programmable).
This probably is one of those cases where evolution happens fairly slowly but surely. There is a starting point and things will get slowly better(faster, more programmable).
Last edited:
Depends on if they use SDF and CSG only for modeling, like mentioned in the old paper. I think so. Full scene SDF always sounds too memory costly. Compare with Claybooks restrictions about scene size and materials/texturing for example.Even without RT hardware, I think so. SDF strikes me as similar to CSG is terms of mathematical resolving.
I may be wrong, but somebody said they moved back closer to the 'brick engine', also mentioned in the paper. This was voxels with volumetric content. HW RT could then be useful for finding those voxels. (I think they use those coarse voxel polys also for occlusion queries, which was why it was mentioned somewhere)
One question in my mind is that how willing are developers to spend time with low level api when even the high level API seems to be too much time(aka. money) to invest in? Does low level API even make sense until the higher level API use is widespread and there is widespread requests from many developers to add specific bits of programmability into the hw/api. These requests would likely come to public via gdc talks/post mortems/tweets where the big players would say hey we did this, its shipping, now we know we need x to make things that much better for next title.
I'm not working in game industry,but i assume your concerns don't apply to most.
Smaller Indie teams use some U engine, and programming efford spent on U engine is shared by a whole lot of games. So it's worth it.
AAA Studios use their own engines. Few programmers in comparison to many artists. Hiring one programmer more to focus on RT won't hurt the budget, but helps to remain competive. So it's worth it.
Similar threads
- Replies
- 184
- Views
- 25K
- Replies
- 21
- Views
- 6K
- Replies
- 90
- Views
- 13K
- Replies
- 50
- Views
- 15K
- Replies
- 2K
- Views
- 190K