
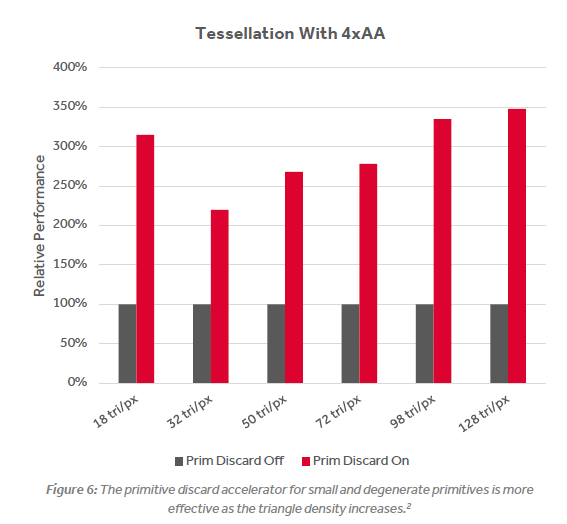
It does not (only in pretty specific circumstances with triangle sizes well below 1 pixel [like 20 triangles per pixel] as I mentioned before and each engine still never exceeds 1 triangle per clock; older GPUs are just pretty slow in that range).In synthetic tests, Polaris gets 2x geometry through put if I'm not mistaken over previous gen cards.
Last edited:

")