
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Speculation, Rumors, and Discussion (Archive)
- Thread starter iMacmatician
- Start date
- Status
- Not open for further replies.
Alessio1989
Regular
We will compare it with the SAPPHIRE R9 390 NITRO w/ backplate (so not a R9 390 reference).
Last edited:
They may be overclocked but some were very marginal.
As an example Sapphire R9 390X TRI-X, this has an OC of 5MHz over the spec; 1055MHz to 1050MHz.
Also its memory clocks are identical to reference at effective 6GHz.
http://www.sapphiretech.com/productdetial.asp?pid=D40475DB-8BD0-40F6-8C33-F12D63272AEC&lang=eng
They were not the only ones to give such a small OC that it is in essence reference/to spec, but the more extreme products had a GPU clock of 1100MHz, so still below 5% clock increase to reference spec.
Cheers
As an example Sapphire R9 390X TRI-X, this has an OC of 5MHz over the spec; 1055MHz to 1050MHz.
Also its memory clocks are identical to reference at effective 6GHz.
http://www.sapphiretech.com/productdetial.asp?pid=D40475DB-8BD0-40F6-8C33-F12D63272AEC&lang=eng
They were not the only ones to give such a small OC that it is in essence reference/to spec, but the more extreme products had a GPU clock of 1100MHz, so still below 5% clock increase to reference spec.
Cheers
Last edited:
Jawed
Legend
So this guy appears to have RX 480:
http://www.overclock.net/t/1603915/coming-soon-unofficial-polaris-owners-thread/40#post_25297979
The GPU-Z screenie shows revision "C7". I don't remember ever having seen a revision that far. So, I had a rummage and found Fury X is revision C8:
http://forums.anandtech.com/showthread.php?t=2441548
I can't help thinking Polaris has had a troubled birth.
So, is that revision meaningful?
http://www.overclock.net/t/1603915/coming-soon-unofficial-polaris-owners-thread/40#post_25297979
The GPU-Z screenie shows revision "C7". I don't remember ever having seen a revision that far. So, I had a rummage and found Fury X is revision C8:
http://forums.anandtech.com/showthread.php?t=2441548
I can't help thinking Polaris has had a troubled birth.
So, is that revision meaningful?
I think that's a given. There's always some games that are uniquely suited for a particular architecture. I'm sure that diehard AotS players will love the 480.Well in some apps cf 480 > 1080 > sli 980. That suggests it's reasonable to expect 980 level performance out of the box at least in some apps.
")
Love_In_Rio
Veteran
https://youtu.be/eUiaJXLoKnE
Attention to the board wattage at the end of the video...If true this gen AMD will be in big trouble.
Attention to the board wattage at the end of the video...If true this gen AMD will be in big trouble.
iMacmatician
Regular
https://youtu.be/eUiaJXLoKnE
Attention to the board wattage at the end of the video...If true this gen AMD will be in big trouble.
That's just Furmark. it can be as high or as low as AMD limits it.
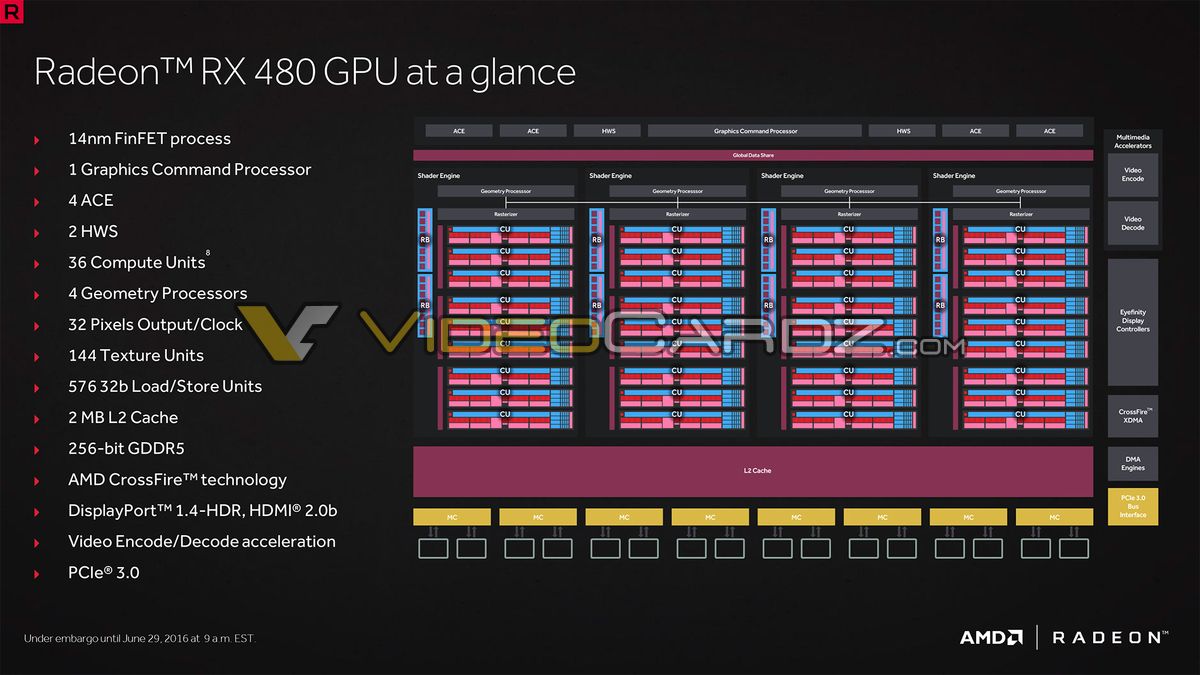
2 on 1, 8 on 4.How many ACE's do the console chips have?
2 for 12, and 8 for 18.
(unnecessarily-easy-cryptic-response because... idk.
How many ACE's do the console chips have?
You mean XB1 and PS4? 2 and 8 I think.
Looks like the L2 partition size has been doubled over GCN 1.2.From Videocardz: "Raja’s Super Secret Cigar Stash."
And what's with the dedicated L/S units -- 16 per CU?
They've been there since birth of GCN.Looks like the L2 partition size has been doubled over GCN 1.2.
And what's with the dedicated L/S units -- 16 per CU?
On the level shown in the slides, there's no new units, no discarded units, no bigger caches or anything
Yes, the current gen ones.
Kinda wish it was 8 ACE's 64 ROPs, but I understand price points.... and if you have to cut something that makes alot of sense.
The Fury diagrams initially had 8 ACE blocks, then 4 and 2 HWS blocks after AMD got around to changing them.
The number of queues in memory and in hardware do not need to be 1:1 if that is enabled.
Polaris at a high level seems to inherit a number of other items from Fiji (or Carrizo?) like adaptive clocking and enhanced caching of vertices for improved instancing.
Interestingly, TrueAudio's dedicated block appears to be gone, so AMD appears to be more confident in its latency and synchronization than it did when the block was first introduced. Being able to reserve CUs ahead of time in order to ensure they are free for rapid wavefront launch seems like it is what provides the latency guarantee that was sorely lacking then.
It was something I spitballed as an idea back for the PS4. If Polaris does turn out to be in the PS4 refresh, we can look forward to the return of the 14+4 CU speculation, although it would possibly be 28+8 this time.
As an aside, it does seem like AMD is indicating Fury's delta compression did not turn out to be as effective as Maxwell, with Polaris apparently now in that range of effectiveness. Possibly, the sheer amount of unused bandwidth made it difficult to make the efficiency improve.
It's kinda cool to see 128tri/px instead of 128px/tri.
I have no idea how common these kind of mini triangles really are for realistic workloads, but I assume that it will help them with extreme tessellation regimes.
The slide says that primitive discard benefits improve with increased MSAA levels. Why is that? All other things equal, the number of samples points increased and gets more dense with improved MSAA. You'd think that this increased the chance that a triangle will hit a sample point and reduces that discard rate?
I have no idea how common these kind of mini triangles really are for realistic workloads, but I assume that it will help them with extreme tessellation regimes.
The slide says that primitive discard benefits improve with increased MSAA levels. Why is that? All other things equal, the number of samples points increased and gets more dense with improved MSAA. You'd think that this increased the chance that a triangle will hit a sample point and reduces that discard rate?
Last edited:
. If Polaris does turn out to be in the PS4 refresh, we can look forward to the return of the 14+4 CU speculation, although it would possibly be 28+8 this time.
OMG after more than 2 years someone has reminded me of that 14+4 debate.
Good old times.
- Status
- Not open for further replies.
Similar threads
- Replies
- 90
- Views
- 13K
- Replies
- 2K
- Views
- 189K
- Replies
- 20
- Views
- 5K