If AMD fixes the on-chip latency in Zen, there will be much bigger perveived difference between DDR/GDDR/HBM. With Jaguar, the difference between GDDR and DDR in latency is minimal. I would hope that HBM is slightly lower latency than the others, because it is so close to the die (same interposer), even if the technology itself adds some cycles. Is there anything pointing to the other direction? Is HBM designed solely for GPUs (to replace GDDR) or has there been mentions about using it on CPUs (to replace DDR4)?
I did some googling to confirm my recollection, and with the speed of light giving ~.3 meters per nanosecond and even with copper signaling being at least a third slower, the distance between the chips itself is not a major contributor. Other factors like needing less to drive the signals might save some time, but that is coupled with a bus that is clocked slower.
I am trying to find a citation for a rather informal characterization that HBM takes a little longer to deliver the initial part of a burst than GDDR5, but can finish the burst faster.
The raw number of channels can help with loaded latency and increase the CPU's ability to spread accesses over more channels, potentially reducing the number of turnaround penalties incurred.
What doesn't necessarily change is the time it takes to fall through the cache hierarchy and traverse the uncore, which AMD hopefully improves.
On the other side, there is the internal logic, routing, and latency of the DRAM arrays.
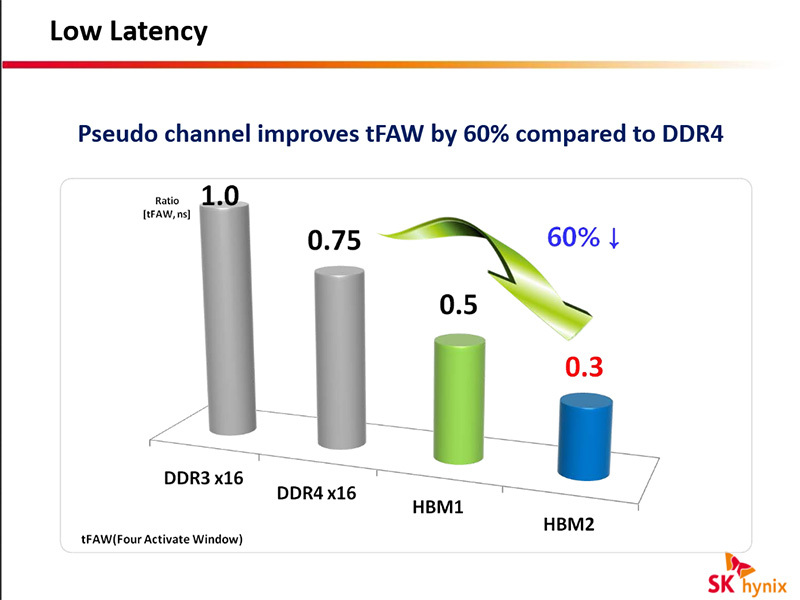
The arrays have not scaled in latency for years, and DRAM devices have a number of latencies that are measured in wall-clock time, not device speed.
Hynix has marketed HBM for other device types, like networking, but I don't recall a strong push to replace main memory. Perhaps some classes of consumer device can, although WideIO is liked by mobile, and DDR4 will be hard to beat in terms of capacity and pricing.