whitetiger
Newcomer
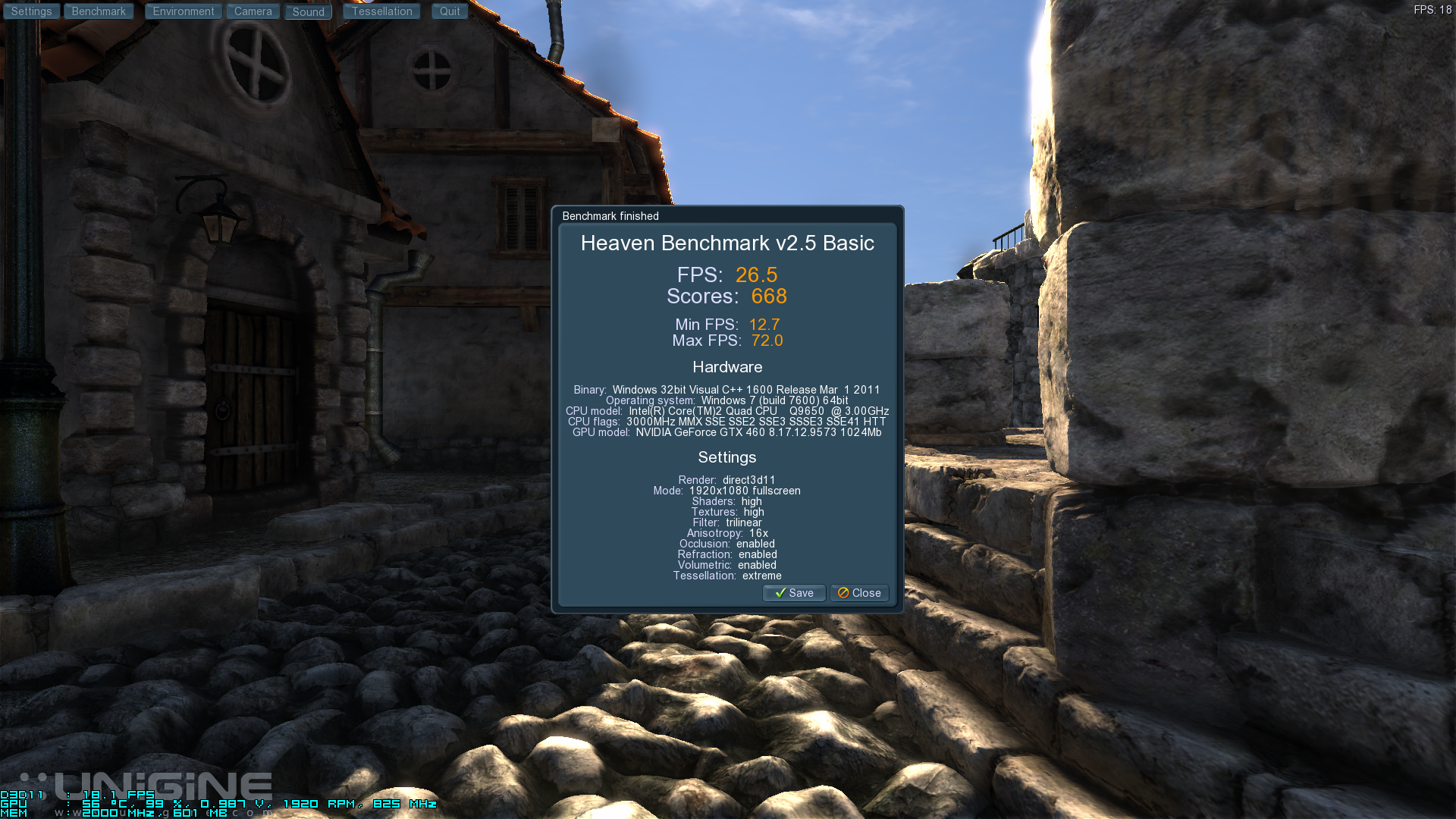
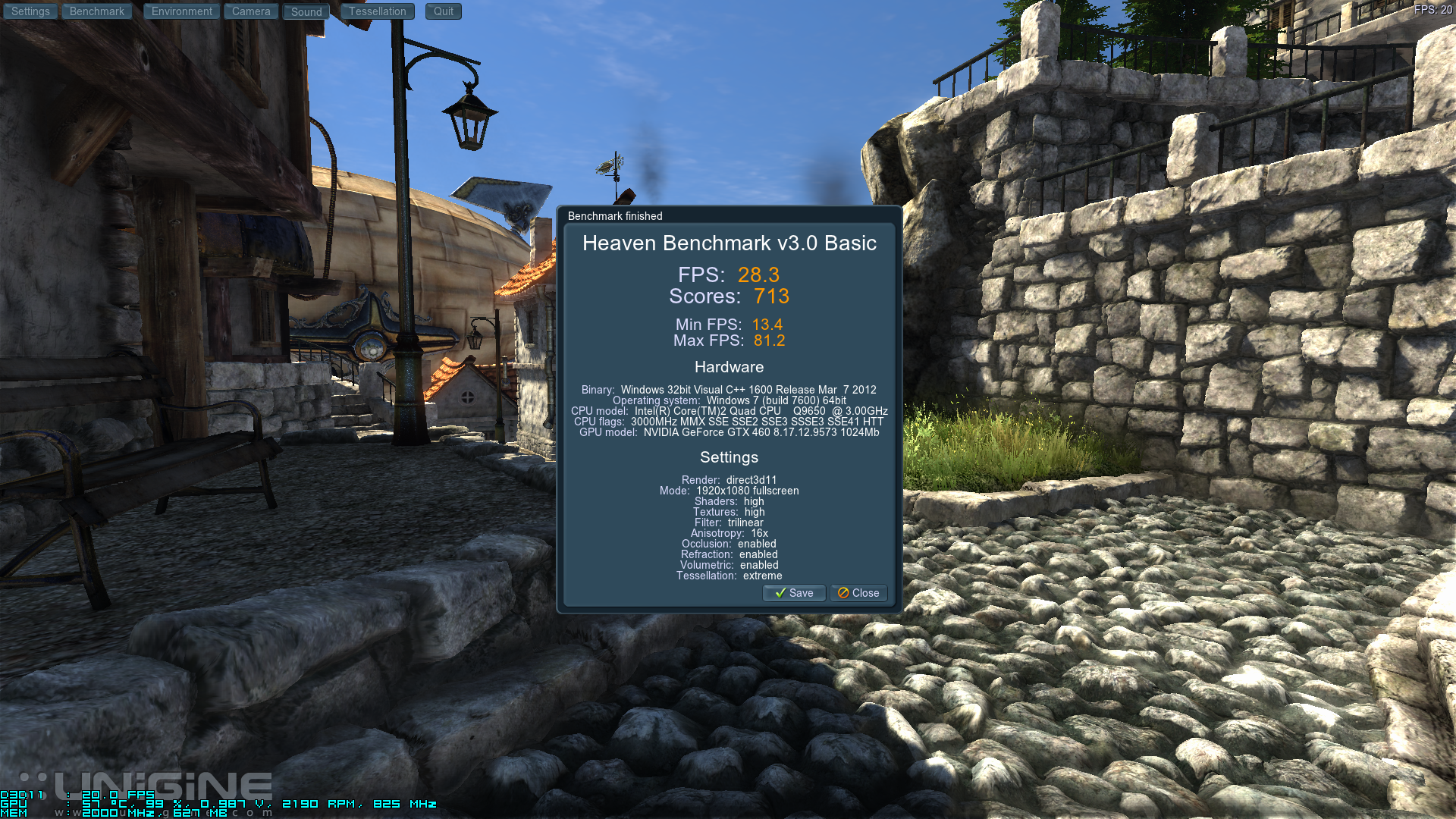
Well, somebody once claimed that it is fundamentally impossible to have 4x distributed geometry processing without having massive latency and gargantuan power consumption. That same someone inexplicably continued to prove this by pointing at, wait for it: a cell characterization problem that was fixed with a metal patch. (WTF?) Then he murmured something about crossbars too, which is funny, because I didn't really expect a crossbar that serves memory to have much to do with distributing geometry at the front-end. Right? It made him even speculate that GK104 would only have 2x geometry, because that's what sensible people do.
It all makes me wonder: what if Nvidia had used a 2x configuration instead of 4x, how much lower do you think the power of GK104 could have been?
What a missed opportunity...
Edit: I forgot the best one: the distributed geometry architecture is responsible for increase power consumption during compute. You can't make this up...
My favorite was going from a statement that Fermi would be terrible at Tesselation, to claiming Fermi had *too much* tesselation, when it turned out that Fermi was actually quite good at Tesselation..
Last edited by a moderator: